MONOREPO
What is a Monorepo?
- A monorepo is a single repository containing multiple distinct projects, with well-defined relationships
Monorepo ≠ Monolith ✋
A good monorepo is the opposite of monolithic!
Will we have to release all on the same day? I don’t like monoliths!
It’s a common misconception, which comes from a strong association of a repository with a deployment artifact.
But where you develop your code and what/when you deploy are actually orthogonal concerns.
Moreover, it’s actually a good CI/CD practice to build and store artifacts when doing CI, and deploy the stored artifacts to different environments during the deployment phase. In other words, deploying an application should not require access to any repository, one or many.
So monorepo !== monolith.
Quite the contrary, because:
- Monorepos simplify code sharing and cross-project refactorings
- Lower the cost of creating libs, microservices and microfrontends.
=> often enables more deployment flexibility.
Not just “code colocation”
Consider a repository with several projects in it. We definitely have “code colocation”, but if there are no well defined relationships among them, we would not call it a monorepo.
Likewise, if a repository contains a massive application without division and encapsulation of discrete parts, it’s just a big repo not a monorepo.
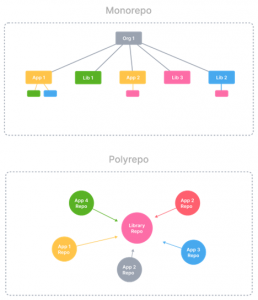
Multirepo
one-repo-per-project
| Multi repositories | |
| Pro | Con |
| One repo per module | One view of the complete system is hard to get |
| Security per repo | Tedious stakeholder management |
| Pipeline per repo – makes it fast | Changes might require updates in multiple repos |
- code sharing: To share code across repositories, you’d likely create a repository for the shared code.
- code duplication: so teams just write their own implementations of common services and components in each repo
- Costly cross-repo changes to shared libraries: the developer needs to set up their environment to apply the changes across multiple repositories
- Inconsistent tooling: Each project uses its own set of commands for running tests, building, serving, linting, deploying, and so forth.
Monorepo
stores everything related to a project in a single repository
| Mono repository | |
| Pro | Con |
| Complete view of the entire system | Grows very large (in size and complexity) |
| Easy to watch and manage | Discipline and processes are required |
| Uniform standards across projects | Tedious access management |
| Easy dependency management | |
Guidelines
-
- Scopes: The folders act as scopes to make sure code artifacts are only visible when they should be. This allows to extract common tasks quickly and maintainers can easier reason about where the error lies.
- One ancestor: Version control builds a hierarchical representation of the code and its changes. Therefore, specialized versions (e.g. a custom fix for a unique problem) can be maintained much easier as change sets are compatible.
- Big pictures: With everything in one place there is no need to copy code between repositories or to look for infrastructure as code files and documentation.
- Good practice: A monorepo requires teams to work with each other. By merging code only with a pull request (PRs), teams review each other’s code which breaks silos and improves code quality.
- Process: A basic setup is to have two main branches, following the GitFlow approach:
- main: This branch shows what currently is running in production
- develop: The latest and greatest features currently deployed in a testing environment
- Automation: Monorepos have to use pipelines to do the following:
- Run build and test (CI) before enabling a merge into the dev/main branches
- One-click deployments of the entire system from scratch
- File and repository sizes: Git’s large file system (LFS) which diverts files by extension to a blob store, replacing it by a reference in the repo

Tools
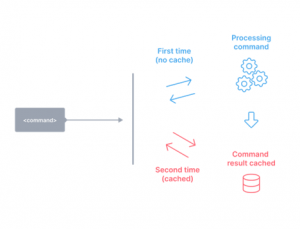
- Local computation caching: The ability to store and replay file and process output of tasks. On the same machine, you will never build or test the same thing twice.
-
-
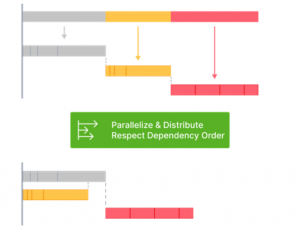
- Local task orchestration: The ability to run tasks in the correct order and in parallel.
-
-
-
- Distributed computation caching: The ability to share cache artifacts across different environments. This means that your whole organisation, including CI agents, will never build or test the same thing twice.
-
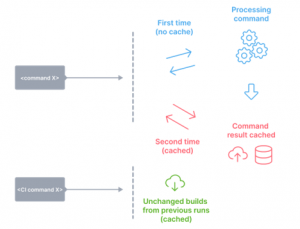
-
- Distributed task execution: The ability to distribute a command across many machines, while largely preserving the dev ergonomics of running it on a single machine.
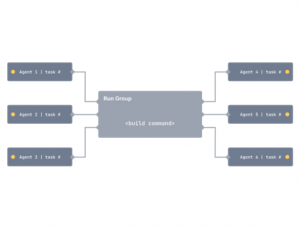
-
- Creating new projects: Use the existing CI setup, and no need to publish versioned packages if all consumers are in the same repo.
- Atomic commits across projects: Everything works together at every commit. There’s no such thing as a breaking change when you fix everything in the same commit.
- Developer mobility: Get a consistent way of building and testing applications written using different tools and technologies.
- Transparent remote execution: The ability to execute any command on multiple machines while developing locally.
- Detecting affected projects/packages: Determine what might be affected by a change, to run only build/test affected projects.
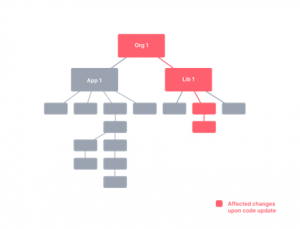
- Workspace analysis: The ability to understand the project graph of the workspace without extra configuration.
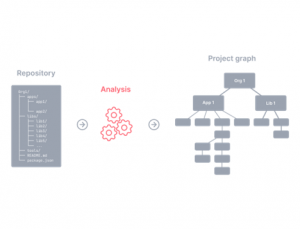
- Dependency graph visualization: Visualize dependency relationships between projects and/or tasks. The visualization is interactive meaning you are able to search, filter, hide, focus/highlight & query the nodes in the graph.
- Code sharing: Facilitates sharing of discrete pieces of source code.

- Consistent tooling: The tool helps you get a consistent experience regardless of what you use to develop your projects: different JavaScript frameworks, Go, Rust, Java, etc.
In other words, the tool treats different technologies the same way.
For instance, the tool can analyze package.json and JS/TS files to figure out JS project deps, and how to build and test them. But it will analyze Cargo.toml files to do the same for Rust, or Gradle files to do the same for Java. This requires the tool to be pluggable.

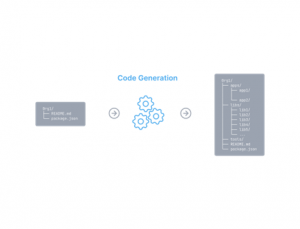
- Code generation: Native support for generating code
- Project constraints and visibility: Supports definition of rules to constrain dependency relationships within the repo. For instance, developers can mark some projects as private to their team so no one else can depend on them. Developers can also mark projects based on the technology used (e.g., React or Nest.js) and make sure that backend projects don’t import frontend ones.
Examples

Bazel(by Google)
“A fast, scalable, multi-language and extensible build system.”

Gradle(by Gradle, Inc)
“A fast, flexible polyglot build system designed for multi-project builds.”

Lerna(maintained by Nrwl)
“A tool for managing JavaScript projects with multiple packages.”

Nx(by Nrwl)
“Next generation build system with first class monorepo support and powerful integrations.”

Rush(by Microsoft)
“Geared for large monorepos with lots of teams and projects. Part of the Rush Stack family of projects.”

Turborepo(by Vercel)
“The high-performance build system for JavaScript & TypeScript codebases.”
![]()
- Date 18 mars 2024
- Tags